Citations are central to scholarly life. Authors cite to characterize the
state of a scientific field and to identify influential works. However,
writers use citations for different purposes and this varied purpose
influences uptake by future scholars.
Unfortunately, our understanding of how scholars use and frame citations
has been limited to small-scale manual citation analysis of individual
papers. We perform the largest behavioral study of citations to date,
analyzing how scientific works frame their contributions through different types
of citations and how this framing affects the field as a whole.
We introduce a new dataset of nearly 2,000 citations annotated for their
function, and use it to develop a state-of-the-art classifier. Label the
papers of an entire field, Natural Language Processing (NLP), we show how
differences in framing affect scientific uptake and reveal the evolution of
the publication venues and the field as a whole. We demonstrate that authors
are sensitive to discourse structure and publication venue when citing, and
that how a paper frames its work through citations is predictive of the
citation count it will receive. Finally, we use changes in citation framing to
show that the field of NLP is undergoing a significant increase in consensus.
As a part of the paper, we are releasing our annotated dataset, all code and
materials used to construct the classifier, and a fully-labeled version of
the ACL Anthology Reference
Corpus (Version 20160301) where each citation has been annotated for its function.
The paper Measuring the Evolution of a Scientific Field through Citation Frames describes the dataset and classifier in details and
includes experiments showing how citation function can reveal changes in
scholarly behavior.
Getting started (Code download)
All the code and resources are available
on GitHub
1. Manually annotated citation data from the ACL Anthology
· Annotated data (13MB)
This data contains the citations annotated data by citation function. Each
citation label is included within a larger JSON file corresponding to the
parsed and preprocessed paper in which the citation occurs. Due to a
preprocessing change, a small number of instances from the data described in
Table 2 in the paper were unintentionally excluded from the classification
experiments, while a small number of new instances were added due to better
data handling. The data described in Table 2
is here and the exact
instances used in classifier experiments
is here. Post hoc
experiments have shown no statistically significant difference in classifier
performance between the three datasets.
3. Reformatted ACL Anthology Reference Corpus (ARC) with canonicalized citations
· JSON-converted ARC with Canonical IDs (1.9GB)
· Canonicalized ARC Paper IDs (42MB)
This archive contains the whole ACL Anthology parsed and reformatted into
the JSON format used by our citation classification system.
2. Converted data from Teufel (2010) in our citation function categorization
· Converted Teufel data (13MB)
This data has been converted into our JSON format, parsed, and where
possible, had its references linked to canonical identifiers in the ACL
Anthology or external identifies.
4. ARC citation network with automatically-assigned citation functions
· Citation Graph (17MB)
· Canonicalized ARC Paper IDs (42MB)
For those interested in network analysis, this file contains the citation
network between papers in the ACL Anthology and citations papers outside of
the ACL Anthology, which have been given canonicalized IDs (e.g., citations
to WordNet). This release provides meta-data on the identifiers.
Citing the paper, data, or classifier
Measuring the Evolution of a Scientific Field through Citation Frames.
David Jurgens, Srijan Kumar, Raine Hoover, Dan McFarland, Dan Jurafsky. Transactions of the Association for Computational Linguistics (TACL). 2018
@article{jurgens2018citation,
title={Measuring the Evolution of a Scientific Field through Citation Frames},
author={Jurgens, David and Kumar, Srijan and Hoover,Raine and McFarland, Dan and Jurafsky, Dan },
journal={Transactions of the Association of Computational Linguistics},
year={2018}
}
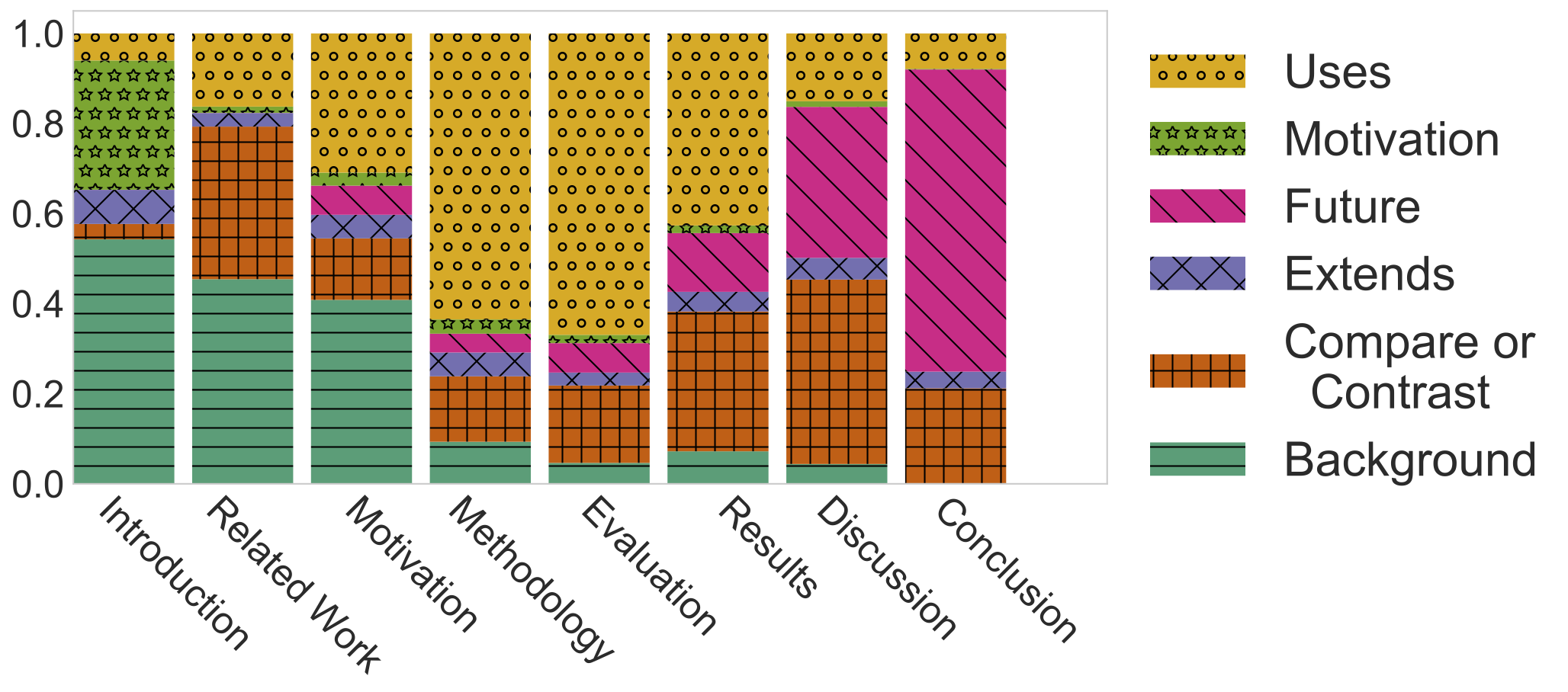
1. Citation Functions Follow Rhetorical Language
Scientific articles commonly follow
a regular structure:
Introduction, Methods, Results, and Discussion. Each of these sections
provide expectations of what kinds of arguments will be made and how they
will be supported. Citations provide a way of making scientific arguments
by framing a paper's contributions with respect to the field. Does the way
citations are used accordingly vary with the expectations of scientific
argumentation in each section? We show citation usage varies substantially,
providing coherent narrative across sections for how scholars substantiate
arguments in the discourse.
2. ACL Workshops really are becoming more conference-like
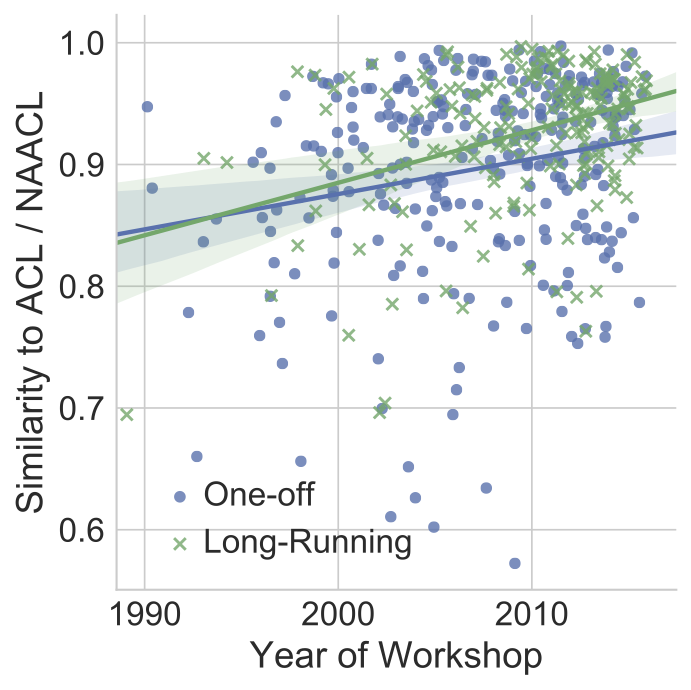
The ACL community hosts a wide variety of workshops on special interests,
which as some
have noted,
act as mini-conferences with their own peer-reviewed proceedings, rather
than being more focused on discussion, panels, and invited talks as in
some fields. We observed that conference and workshop papers typically
cite in different ways, with the largest difference being due to
conference papers including more comparisons of their work with others.
Together, the way a paper cites is an argument for its quality; conference
paper are expected to look and cite like other high-quality papers.
Are workshops following this trend by having their papers cite in a more
conference-like way? We compare how similar each year's workshop papers'
citation behaviors are to the conferences' behaviors and find that,
indeed, workshops papers appear more conference-like. Further, workshops
that happen each year accelerate this process, perhaps due to
institutional knowledge and norms, and are even more mini-conference like.
3. NLP is becoming a Rapid Discovery Science
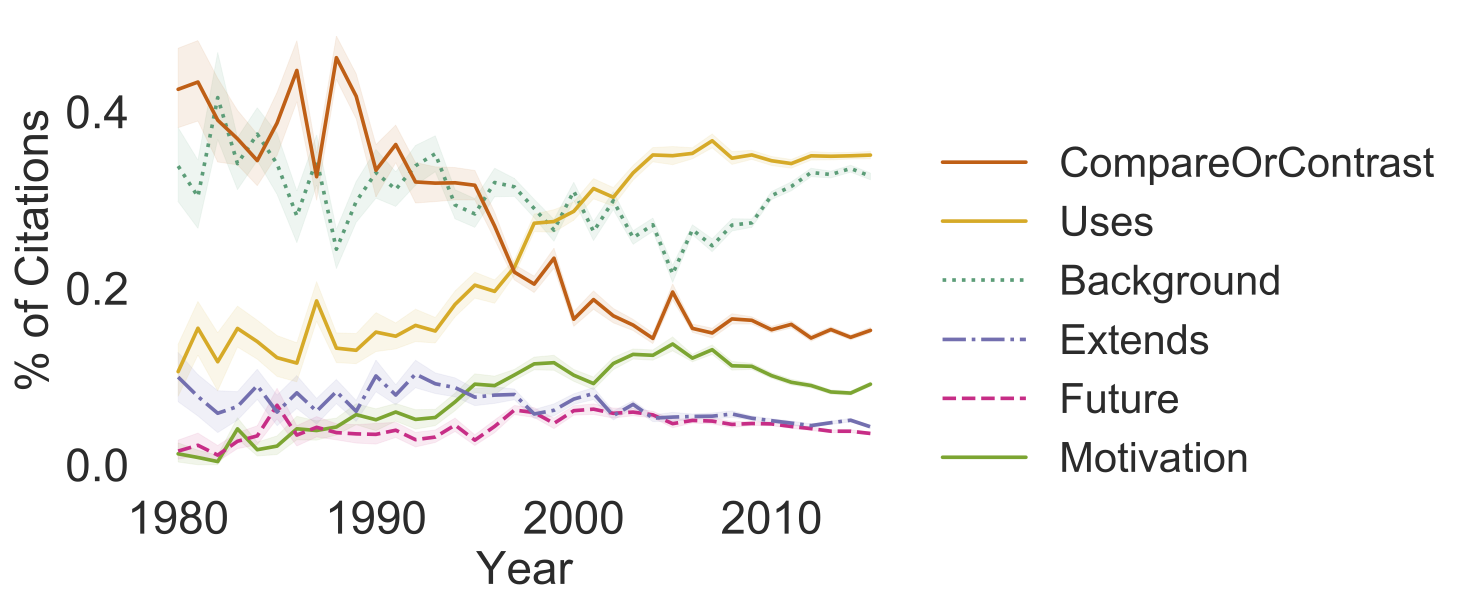
As scientific fields evolve, new subfields initially emerge around methods
or technologies which become a focus of collective puzzle-solving and
continual improvement. NLP has witnessed the emergence of several such
subfields from the early grammar based approaches in the 1950s-1970s to
the statistical revolution in the 1990s to the recent deep learning
models. Collins
(1994) proposed that a field can undergo a particular shift, to what
he calls rapid discovery science, when the field (a) reaches high
consensus on research topics as well as methods and technologies, and (b)
then develops genealogies of methods and technologies that continually
improve on one another. This shift characterizes natural sciences, but
not many social sciences, which are instead more likely to engage in
continual contesting and turnover of core methods and assumptions. Has
NLP undergone a shift to rapid discovery science? Examining trends in how
NLP authors cite one another's work, we find that (1) authors began to
compare with fewer works and instead just acknowledge these works instead
as background literature and (2) the field increasing compares against the
same works, as well as increasingly using the same resources and tools.
Together, these trends show increase consensus: rather than having to
defend a contribution from multiple vantage points, authors simply compare
against the same works that the whole community agrees are sufficient to
establish a contribution.
GitHub: Our classifier
is on
GitHub. For bug reports and patches on the code or for any issues you
might run into with the data, please file a GitHub issues. We also
welcome any pull requests for new features or to make the pipeline work
with other kinds of data.